
Kubernetes Rightsizing Automation: The Trust Gap in Production
Published in May 2026
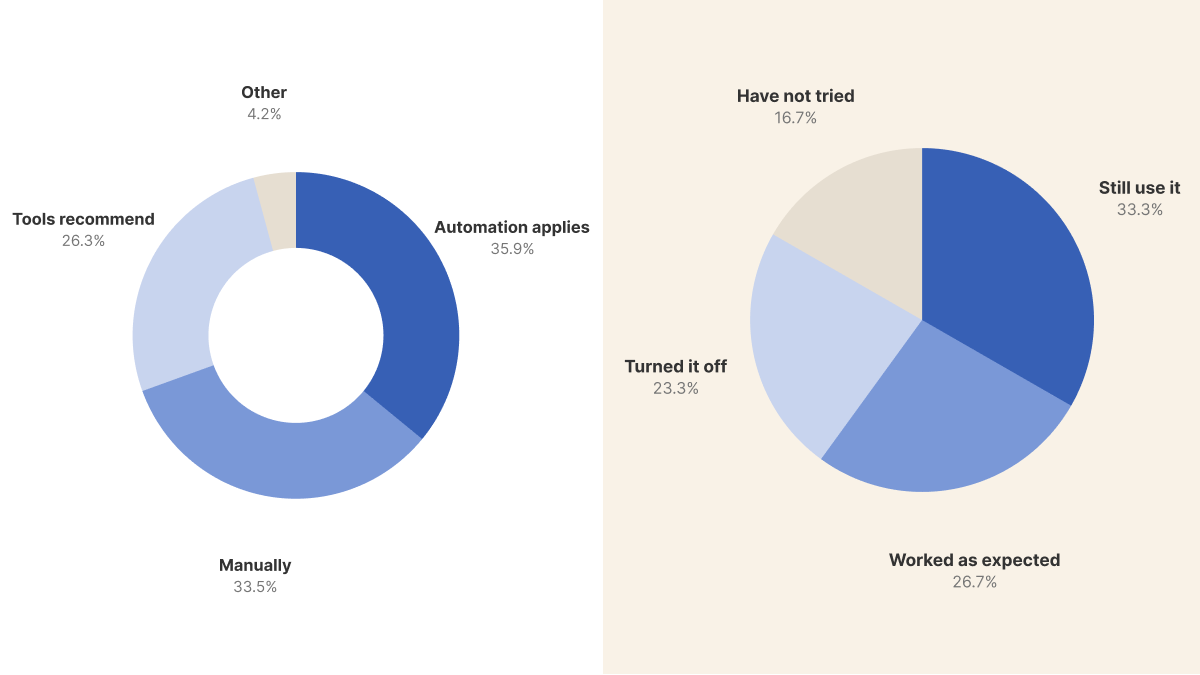
We asked 323 Kubernetes practitioners about trust in rightsizing automation. The poll covered who sets CPU and memory requests, whether teams have pulled back from auto-rightsizing, and what they need before allowing changes without approval. 59.9% still keep a human in the loop for request changes. 56.7% said recommendations made them pause or pull back. 58.3% chose hard limits or rollback before letting automation act on its own.
Kubernetes teams have spent years automating releases, rollbacks, scaling, and infrastructure changes.
Rightsizing CPU and memory requests still feels different.
The Kubernetes Automation Trust Gap study found the same pattern: teams often trust CI/CD to ship code, while production resource settings still get manual review.
A bad request change can affect scheduling, availability, throttling, OOM behavior, and cost at the same time.
Disclosure: StormForge by CloudBolt sponsored this poll series to explore how Kubernetes teams think about rightsizing automation. The analysis below uses the community responses collected across the three polls.
This survey focused on three practical questions:
- Who sets CPU and memory requests today
- Whether teams have pulled back from optimization recommendations
- What they need before allowing automatic changes.
Who Sets Your CPU and Memory Requests?
The first poll asked how teams set CPU and memory requests for production workloads.

Automation was the largest single answer, with 60 respondents saying automation applies changes directly.
Combined, the two human-in-the-loop answers were larger: 100 respondents, or 59.9%, either set values manually or used tools only as recommenders.
Most teams treat automation as a recommendation engine rather than a final authority.
Ranjit Rudra captured the operational reason for caution:
In most cases, teams still prefer a human-in-the-loop approach because CPU/memory changes directly impact cost, scheduling, and cluster stability.
The concern is practical: the change may look small in a manifest, but it can affect pod placement, node utilization, latency, and failure modes.
Other comments showed that manual changes do not always mean ad hoc changes.
Abhijith Ravindra's comment was: "Manually - GitOps."
That is a useful distinction because manual approval can still happen through a controlled delivery workflow rather than through ad hoc dashboard changes.
Oleksii K said they set requests manually and were looking at VPA in Kubernetes 1.33+.
Comments showed that decision authority was the focus.
What this means for you:
For teams reviewing every recommendation, improve recommendation quality, audit trails, and policy limits before expanding autonomy.
These controls give operators a smaller next step than full auto-apply.
Have Bad Recommendations Changed How Teams Use Auto-Rightsizing?
The second poll asked whether a resource optimization recommendation had ever made teams pause or pull back automation in production.
This was deliberately framed around experience, not opinion.

Among all respondents, 34 out of 60 said a recommendation had made them pause or pull back.
The split is important: 14 respondents turned automation off, while 20 still use it despite having seen a concerning recommendation.
Following concerning recommendations, some teams disable automation while others continue with more review, narrower scope, or stronger guardrails.
Amin Astaneh pointed to an organizational problem behind the technical one:
There is typically too much distance between who CHOOSES a vendor and who USES it. What's the point in paying a subscription for automation if the operators don't trust it?
This comment reveals a gap between procurement and operations.
Operators require reliable production behavior, as procurement claims and dashboards alone do not establish trust.
Without operator trust, the tool remains a manual review queue.
What this means for you:
If recommendations have caused concern, the response can be gradual. A practical path starts with recommendation mode, then scoped auto-apply for low-risk workloads, and broader automation only after rollback and guardrails are proven.
Conditions for Unsupervised Rightsizing Automation
The final poll asked what teams need before allowing a tool to adjust CPU and memory without approval.

Hard limits were the top answer, chosen by 39 respondents.
Transparency was close behind: 34 respondents wanted full visibility into the tool's reasoning.
Hard limits plus rollback accounted for 56 respondents, or 58.3%, making guardrails the dominant theme.
The vote split shows that teams pair transparency with controls.
A tool can clarify why it reduced memory, but explanations do not prevent readiness failures or OOMKills when it misses a traffic pattern.
What this means for you:
Bounded autonomy is the bar.
A credible rightsizing workflow should show why it made a recommendation, enforce limits before applying changes, and reverse changes quickly when health signals degrade.
The absence of transparency, limits, and rollback leads many teams to keep a human approval step.
Summary
Practitioners require proof and boundaries before handing control to rightsizing automation.
Automation was the largest single answer in the first poll.
When we count manual and recommendation-driven workflows together, most respondents still keep a human in the loop.
The second poll shows why: more than half of respondents said a recommendation had made them pause or pull back.
The third poll highlights that practitioners require transparency, hard boundaries, and rollback to manage risk and recover from incorrect recommendations.
Production workload operators require automation that understands risk, respects limits, and can recover quickly when a recommendation is wrong.