
Blind and Indivisible: GPU Resource Management in Kubernetes
Published in March 2026
TL;DR: We asked 797 Kubernetes practitioners how they manage GPU resources. Half prefer using several smaller GPUs instead of one powerful one (50% vs 18.5%). About 45% would split workloads across multiple GPUs to avoid wasted resources, and 71% would use alternative signals, such as latency or power draw, if GPU metrics were unavailable.
GPU workloads are becoming more common in Kubernetes clusters, but the available tools and abstractions are lagging behind.
With CPUs, you can request fractional usage and view detailed usage metrics.
In contrast, Kubernetes only lets you allocate whole GPUs, and you get limited insight into how they're being used.
Disclosure: Kubex sponsored this research. They provided the overarching theme but had no input on the actual questions or analysis.
This survey set out to learn how practitioners make GPU resource decisions: how they pick between GPU types, handle Kubernetes' integer-only allocation, and manage without utilization metrics.
The results show that most people value flexibility and cost efficiency over raw power, but they are constrained by how Kubernetes currently handles GPUs.
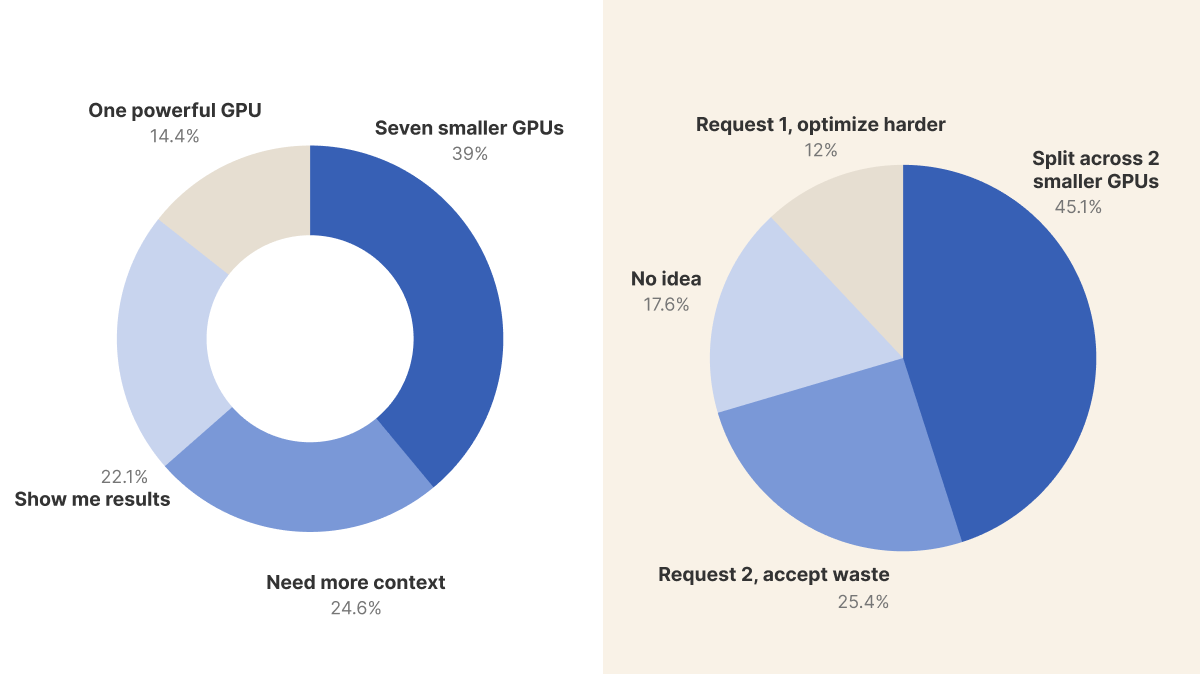
For a New Project, Would You Pick 1 Big GPU or 7 Small Ones?
The first poll asked people to choose between one NVIDIA H100 node (about $30,000/month, 80GB shared memory) or seven T4 nodes (about half the total cost, 7x16GB or 112GB of separate memory).

When we exclude the 'show me results' votes, half of the respondents chose smaller GPUs, while only 18.5% picked the single powerful GPU.
Choosing several smaller GPUs is a practical choice.
It offers greater isolation, better fault tolerance, and lower per-unit memory cost.
However, 31.5% said they needed more context, showing that this decision is not always simple.
@MForjaTech on Twitter explained the trade-off: "If you're doing large-model training, video generation, or anything that needs big shared VRAM, one powerful GPU wins. Memory fragmentation across 7 cards can become your bottleneck fast."
Amine Saboni echoed this: "It depends on the final usage. For some tasks (benchmarking, offline inference), a multi-GPU instance with 8 T4 could be ok, but for online service, CUDA kernels accelerating inference might not be compatible with GPUs of the Tesla generation."
From Telegram, Oleksii K added: "It depends on a library. Ollama performs better on one big."
What does this mean for you?
The best choice depends on your workload.
Training and large-scale inference often require the continuous memory of a single powerful GPU.
On the other hand, serving several smaller models or running batch inference is better suited to multiple smaller GPUs due to their isolation and cost savings.
If your team always chooses the biggest GPU, you might be paying extra for capacity you don't actually use.
Begin by determining your workload's memory requirements.
Does your model fit in a single GPU's memory, or can you split it across multiple GPUs?
Your Inference App Needs 1.5 GPUs. What Do You Do?
The second poll looked at a key limitation: Kubernetes only lets you request whole GPUs, not fractions like you can with CPUs.
So if your workload needs 1.5 GPUs, you have to decide how to handle that.

Most people choose to split the workload across two smaller GPUs rather than waste resources on a larger one or limit themselves to just one GPU.
This shows that teams are willing to deal with more complex setups if it means they don't have to pay for unused GPU capacity.
About 25.4% said they would request 2 GPUs and accept the waste, showing a practical 'just ship it' mindset that values reliability over efficiency.
However, the comments revealed perspectives different from those suggested by the poll options.
Multiple respondents noted that the poll's framing omitted a key technology: NVIDIA Multi-Instance GPU (MIG).
Davide Rutigliano highlighted another option entirely: "Dynamic Resource Allocation. Instead of requesting 1 or 2 GPUs, you can use ResourceClaims to request slices of hardware."
Jan Skalla asked: "Why would you lock yourself to just whole pieces of GPU when MIG, NVIDIA operator, and AIBrix exist?"
KAPIL added: "NVIDIA Multi-Instance GPU (MIG), also tools like runai and weavenet provide schedulers that allow fractions."
From Twitter, Kubernetes with Naveen explained the MIG approach in detail: "Treating GPUs as integers is K8s 101. It's ideal to use MIG to slice an H100 into 7 instances. Request two 3g.40 GB slices to get exactly 1.5 worth of compute without the integer tax or wasted overhead."
Dinesh offered a contrasting perspective: "Always overprovision: end-user convenience/experience/smoothness will rake in more profits than wasted compute costs."
What does this mean for you?
The community's response reveals a gap between Kubernetes' native GPU model and what practitioners actually need.
While the standard device plugin treats GPUs as indivisible units, technologies like MIG and Dynamic Resource Allocation (DRA) are closing this gap.
If you're asking for whole GPUs and end up with wasted capacity, consider MIG partitioning or DRA.
These tools could help you save money without losing performance.
The need to use whole GPUs is a limitation of Kubernetes, not the hardware itself.
If CPU Metrics Disappeared, How Would You Right-Size Containers?
The third poll used a thought experiment to surface how teams would cope with the visibility challenges that GPU workloads already face. Datadog's 2025 State of Containers and Serverless report found most workloads use less than half their requested memory and under 25% of requested CPU, but at least CPU utilization is measurable.
GPUs don't offer the same visibility: standard tools show "busy" but not "productive," and the Linux kernel has no insight into what's happening inside the GPU.

More than 70% of respondents said they would look for other signals rather than give up on right-sizing their resources.
This strong preference for proxy metrics such as latency, power draw, or application logs indicates that teams are accustomed to working with imperfect data.
They're willing to use indirect measurements instead of just overprovisioning.
The 12.7% who would overprovision are taking a cautious approach: if you can't measure, you buy extra capacity. But with GPU prices, this can get expensive fast.
The 10.9% who would "cut blindly and see what breaks" may sound reckless, but this approach has parallels with chaos engineering: intentionally reducing resources to find actual limits.
Only 5.5% would refuse to operate without visibility, the smallest group by far, suggesting that teams generally accept imperfect data as a reality of infrastructure management rather than treating it as a blocker.
What this means for you:
The community's willingness to seek alternative signals is encouraging, but it also highlights the current tooling gap for GPU observability.
Unlike CPU metrics, which are exposed through standard Linux kernel interfaces, GPU utilization data depends on vendor-specific tools like NVIDIA's DCGM or nvidia-smi.
If you run GPU workloads, tracking application-level metrics such as inference latency, throughput, or queue depth will give you better signals for right-sizing than simply looking at GPU utilization percentages.
These application metrics show if the GPU is actually doing useful work, not just if it's busy.
Summary
The survey of 797 Kubernetes practitioners shows a community that handles GPU resource management in practice but still faces limited tool support.
When choosing between GPU types, teams favor smaller, cheaper GPUs (50%) over single powerful ones (18.5%), though nearly a third recognize that the decision is workload-dependent.
The need to allocate whole GPUs is a well-known problem. While 45% would split workloads to avoid wasted capacity, many community members pointed to MIG and Dynamic Resource Allocation as ways to address this issue.
On visibility, 71% would seek alternative signals if metrics disappeared, reflecting a practical acceptance of imperfect data rather than a demand for perfect observability before acting.
These trends show that GPU resource management in Kubernetes is still developing. The current approach uses broad abstractions (whole GPUs only), offers limited visibility (busy vs. productive), and involves high costs ($30,000/month per H100), making it hard to scale sustainably.
Technologies like MIG partitioning and DRA represent the path forward, moving GPU allocation from integer arithmetic to something closer to the granular, metrics-driven approach that CPU management already enjoys.