
Immutable OS for Kubernetes: Where Theory Meets Operations
Published in April 2026
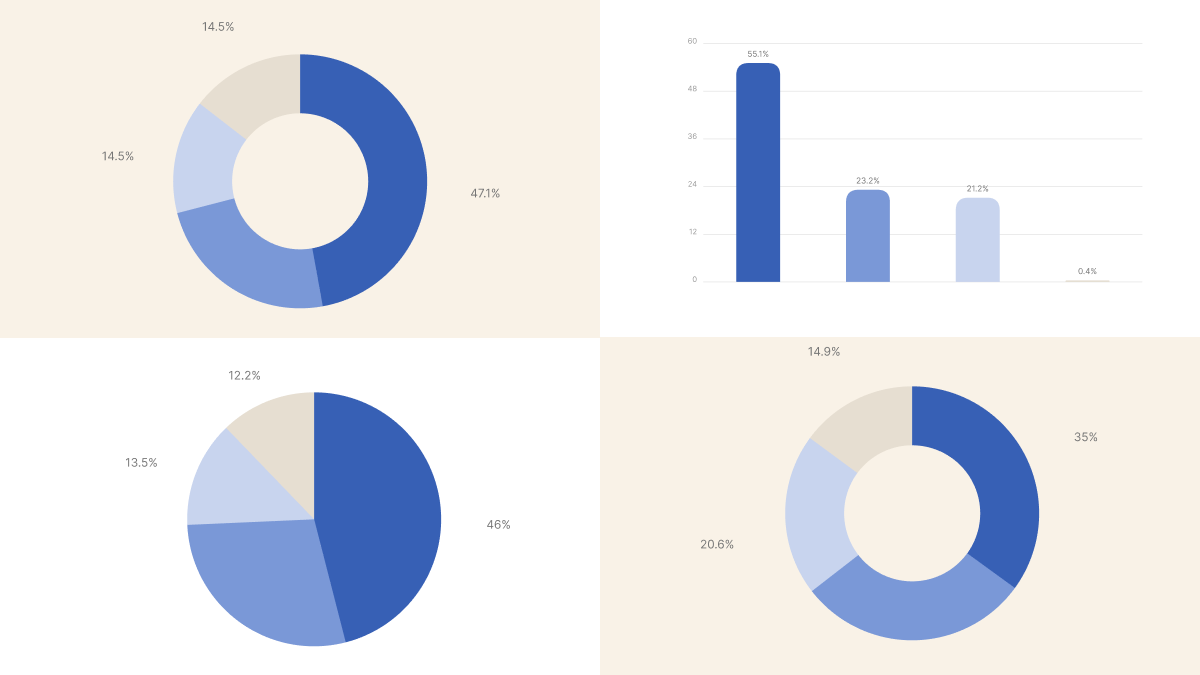
TL;DR: We asked 2,138 Kubernetes practitioners how they update, debug, patch, and customize the OS on their nodes. 47.1% replace nodes instead of patching them, 55.1% check monitoring and logs first during node incidents, 46% say they can patch their fleets within hours, and only 14.9% run heavily customized node images.
The Kubernetes control plane, workloads, and manifests are usually the first to get the GitOps treatment.
The node OS is usually excluded.
This gap is important because how teams manage nodes affects how quickly they can patch CVEs, how much drift builds up over time, and whether a broken node should be debugged or just replaced.
Disclosure: Spectro Cloud sponsored this research to raise awareness on Hadron OS, an immutable OS for Kubernetes. They provided the overarching theme but had no input on the actual questions or analysis.
This survey examined how practitioners manage the OS layer in real-world situations: how they update nodes, respond to misbehaving nodes, patch OS vulnerabilities, and customize their base images.
Many teams already use an immutable approach, but how they implement it varies a lot.
Replacing nodes is common, but heavy customization, ad hoc debugging, and unclear patch timelines still cause challenges.
How Do You Update the OS on Your Kubernetes Nodes?
The first poll asked whether teams treat node updates as in-place maintenance or as a rebuild-and-replace workflow.
This is a clear sign of whether a team sees nodes as long-lasting machines or as disposable infrastructure.
We asked: How do you update the OS on your Kubernetes nodes?

Nearly half of respondents already prefer replacement over in-place patching.
That is a strong signal that the immutable-node idea has moved beyond theory and into mainstream operational practice.
Meanwhile, the next largest group relies on managed cloud providers to handle this task.
That does not mean those teams have adopted an immutable workflow themselves.
Often, the lifecycle is just hidden behind a service boundary.
The comments shed light on why teams are divided.
Mohamed I. noted that for on-prem clusters running on virtual machines, deploying a new VM image is often more efficient than patching an existing one.
Vikram B. described rotating nodes with an AMI provided by the security team, with patches and observability tooling already baked in.
Tijmen V. pointed to Flatcar's update model and coordinated reboots with tools such as kured and FLUO.
Tuan A. linked to a 2026 post on using a bootable container approach for VM patching.
Quentin J. described a similar bootc model as continuous delivery for the base OS itself: update the image definition, let CI build it, and roll forward with rollback support rather than modifying machines by hand.
What this means for you:
The community is already leaning toward image-based node lifecycle management.
The practical takeaway is not that every team must adopt a specific immutable distro tomorrow, but that OS changes increasingly belong in an image pipeline rather than in a shell session on a live node.
A Node Is Misbehaving, and It's Not a Kubernetes Issue. What's Your First Move?
Immutable infrastructure is often seen as a simple solution to node failures: just replace the machine and continue.
In reality, teams still need enough information to tell if a problem is isolated or affects many nodes.
We asked: A node is misbehaving and it's not a Kubernetes issue. What's your first move?

Observability was the top answer, mentioned by more than half of the respondents.
Over half said they would check node monitoring and logs before doing anything else.
Running immutable nodes depends on having enough telemetry to make replacements safe and repeatable.
Replacing a broken node without understanding whether the issue is isolated can hide a broader pattern.
The comments point to a staged playbook rather than a binary choice.
Rauno D. argued for investigation because a failure that happens once may happen again on other nodes, but recommended time-boxing the effort before moving to cordon, drain, and replace.
Tibo B. made the same trade-off explicit: cordon and drain almost immediately, let Karpenter bring up a replacement, but keep the failed node around long enough for a deeper dive if necessary.
Martin C. described a sequence that many teams would recognize: check node monitoring/logs -> SSH and investigate -> cordon, drain, replace.
What this means for you:
An immutable node strategy does not remove the need for diagnostics.
It changes where diagnostics happen and how much time you spend on them.
If your node telemetry is weak, replacing nodes is just a temporary fix.
If your monitoring is strong, replacing nodes is a controlled response instead of a guess.
A Critical OS CVE Hits. How Fast Can You Patch All Your Nodes?
The third poll focused on how teams handle incidents instead of routine operations.
A critical CVE is a real test of whether a team's update process works under pressure.
We asked: A critical OS CVE hits. How fast can you patch all your nodes?

Nearly three-quarters of respondents said they could patch all nodes within hours or days.
Many organizations already have a working process for updating nodes, even if their tools and methods differ.
The remaining quarter shows there are still big gaps in the process.
More than one in eight said it would take weeks to patch, and another one in eight did not know how long it would take.
These answers show there are gaps in governance and process, not just in tools.
Blanka put the immutable position plainly: "If your nodes are also cattle (not pets), you don't patch them; you create new ones without the vulnerability."
This way of thinking aligns with earlier results on node lifecycles.
It also helps explain why patch speeds vary so much.
Teams with image pipelines and automated rollouts face different challenges than those still using manual change windows.
What this means for you:
The real test of an immutable-node strategy is not just being able to describe it on paper.
It's about being able to confidently answer how quickly you can patch your nodes.
How Much Do You Customize the OS on Your Kubernetes Nodes?
The last poll explored why immutable approaches are often harder in practice than they look in diagrams.
A plain, default image is easy to replace.
But an image with security agents, kernel modules, GPU drivers, sysctl changes, and extra hardening is much harder to replace.
We asked: How much do you customize the OS on your Kubernetes nodes?

Most teams do not heavily customize their node OS, but very few use a completely untouched base image.
The biggest group sticks to the default image, while another 29.5% add a few extra components.
So, about two-thirds of respondents could realistically use immutable image rebuilds, provided their additional changes are properly included in the build process.
The group with heavily customized images is smaller at 14.9%, but still significant.
For these teams, adopting immutable Linux is hardest, since every custom kernel, hardening profile, or driver adds to the work of rebuilding and testing images.
Enzo V.'s LinkedIn comment captured that tension well.
He argued that maintaining custom OS images only makes sense when there is a strong reason, such as real-time workloads or a specific feature requirement.
Otherwise, it quickly becomes a hassle and demands a proper build and configuration framework rather than ad hoc changes.
What this means for you:
The practical dividing line is not between mutable and immutable ideology.
It's about whether you can reliably incorporate changes into an image pipeline or still rely on undocumented, team-specific knowledge.
A few well-understood extras are manageable, but deep customization without a solid build process makes node replacement much harder.
Summary
The survey shows that the Kubernetes community is already closer to using immutable node operations than many teams might think.
Nearly half of respondents replace nodes instead of patching them, and 46% say they can patch their fleets within hours.
This shows a real shift toward rebuilding and rolling out the base OS rather than maintaining it by hand.
However, this transition is not yet complete.
More than half of teams still add extras to their base images, 14.9% use heavily customized nodes, and a quarter either need weeks to patch or do not know their patch timeline.
The way teams operate is changing faster than their supporting processes.
Across all four polls, the main takeaway is that immutable infrastructure only works well when paired with strong observability and disciplined image management.
Teams are open to replacing nodes, but they still need monitoring-first debugging, repeatable image builds, and clear ownership of what is included in the base OS.
This is the practical reality of using immutable Linux on Kubernetes today.
For teams heading this way, the next steps are less about ideology and more about building reliable observability, image pipelines, and patch rollouts for the base OS.