
AI Infrastructure on Kubernetes
Published in October 2025
TL;DR: This report presents findings from a four-week survey of the Kubernetes community about their experiences scaling AI workloads. The survey ran throughout October 2025, with each poll open for three days, collecting 917 total responses.
Cloud providers regularly announce support for massive Kubernetes clusters—Google's GKE now handles 65,000 nodes, AWS EKS supports up to 100,000 nodes per cluster.
OpenAI's journey from 2,500 nodes in 2018 to 7,500 nodes in 2021 to 10,000+ today is frequently cited in discussions about AI infrastructure scale.
Over four weeks in October 2024, we asked the community about cluster sizes, GPU utilization challenges, workload separation strategies, and node management approaches.
The results reveal a significant gap between the cutting-edge infrastructure discussed at conferences and the day-to-day realities most teams navigate.
Most organizations operate clusters well under 1,000 nodes, struggle primarily with GPU cost optimization, and are actively seeking ways to maximize their infrastructure investments.
Disclosure: AWS sponsored this research. They provided the overarching theme but had no input on the actual questions or analysis.
Cluster Scale in Production
The conversation around AI infrastructure often focuses on vendor capabilities and high-profile success stories.
Yet there's a substantial gap between what's technically possible and what most organizations actually need.
While cloud providers compete on maximum cluster size and tech giants share their scaling journeys, the majority of teams operate in a different reality.
Understanding this distribution helps contextualize infrastructure decisions and set realistic expectations for what "production scale" means across the industry.
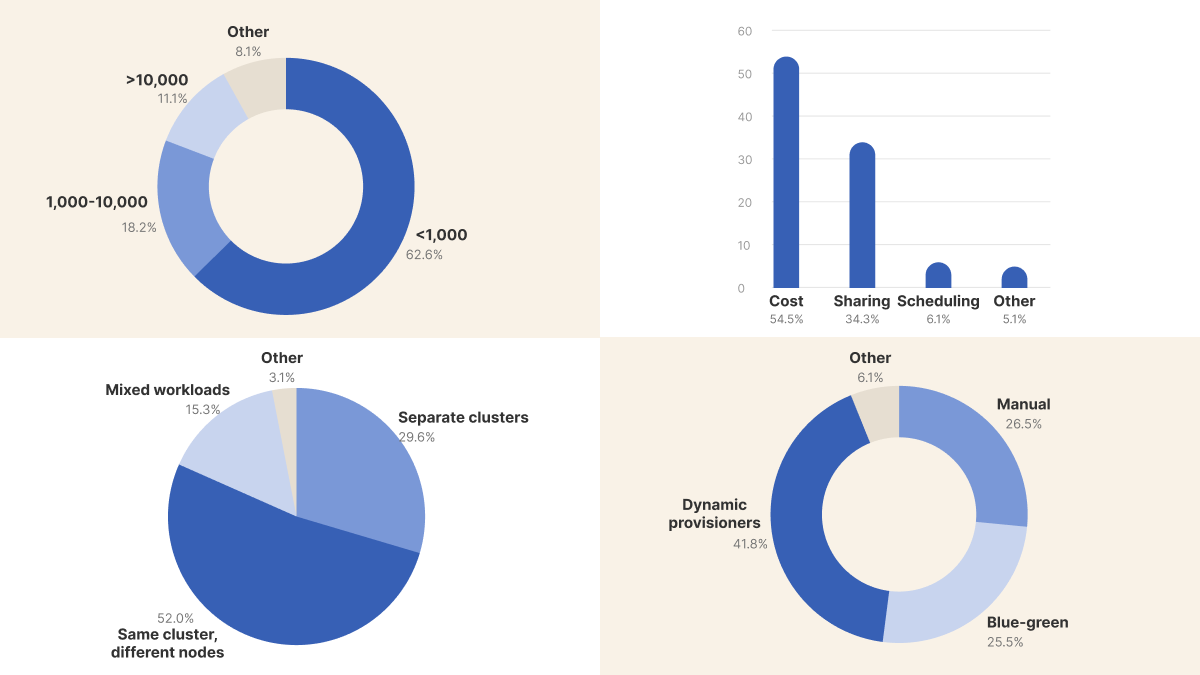
We asked: What's the largest Kubernetes cluster size you've seen in production (or read in the news)?

The results show most organizations operate at modest scale despite vendor capabilities.
The 12% reporting experience with 10,000+ node clusters represents the high end of the distribution—likely engineers at large tech companies or cloud providers themselves.
The remaining 88% work with substantially smaller infrastructure.
What this means for you: Infrastructure decisions should be based on current and near-term requirements rather than theoretical maximum scale.
Organizations operating 500-node clusters don't need to architect for 50,000-node scenarios.
The operational complexity, tooling, and practices that work at smaller scale often differ significantly from hyperscale requirements.
Focus optimization efforts on efficiency within your current scale tier.
GPU Utilization Challenges
GPU costs dominate AI infrastructure budgets, with NVIDIA H100 instances running $10 per hour across major cloud providers.
Understanding whether organizations struggle with cost, multi-tenancy, or scheduling helps identify whether challenges are primarily economic, technical, or organizational.
We asked: What's your biggest challenge with GPU utilization in Kubernetes?

The strong cost signal indicates GPU waste is a universal problem.
The low 7% reporting scheduling delays doesn't necessarily mean orchestration is solved—instead, most organizations haven't reached the scale where queueing becomes their primary concern.
When GPUs sit idle due to underutilization or skills gaps, scheduling efficiency becomes secondary to the more fundamental challenge of productive use.
Ezio commented on Telegram: "Never had a chance to use them" (6 reactions).
This highlights how GPU access doesn't automatically translate to productive use, whether due to lack of use cases, skills gaps, or organizational barriers preventing teams from leveraging available hardware.
DK added: "Challenge is that dev's cant utilise them properly 😄"
The skills gap between having GPUs and using them effectively emerged as a recurring theme.
What this means for you: Before expanding GPU capacity, organizations should measure actual utilization rates.
An underutilized single GPU running at 20% utilization, assuming a $10 hourly rate, wastes approximately $70,080 annually.
The skills gap identified by DK suggests training investments may provide better ROI than additional GPU purchases.
Training and Inference Workload Separation
AI workloads fall into two categories with different characteristics:
- Training is batch-oriented, runs for hours or days, and can tolerate interruptions.
- Inference requires low latency, scales rapidly with user demand, and runs continuously.
We asked the community their preference: Should AI training and inference workloads run on the same Kubernetes cluster?

The preference for unified clusters with node-level separation challenges conventional wisdom about workload isolation.
The community appears to favor consolidation with proper orchestration over complete separation.
@trmatthe commented on Twitter: "Isn't cluster-per-workload antithetical to the intent of k8s? We have orchestration knobs that let us isolate neighbouring workloads, if we get it right."
This captures the philosophical tension: Kubernetes provides node selectors, taints and tolerations, resource quotas, and network policies specifically for multi-tenancy.
Creating separate clusters for every workload type may indicate incomplete use of platform capabilities.
The relatively even distribution across options (29% separation, 51% node-level, 16% mixed) suggests the industry is still exploring optimal strategies.
The 51% preferring unified architecture likely have mature orchestration practices that make consolidation viable.
What this means for you: The choice between unified and separated infrastructure depends on organizational orchestration maturity.
Unified clusters require proper node affinity configuration, resource quotas per workload type, and network isolation strategies.
Organizations with these capabilities in place can reduce operational overhead by managing one cluster instead of multiple specialty environments.
However, teams still building Kubernetes expertise may find separate clusters safer initially.
The operational cost of managing multiple clusters—different upgrade schedules, security policies, and monitoring setups—should factor into the decision.
Node Lifecycle Management
Node rebuilds and patching in Kubernetes present operational challenges, especially for GPU workloads where zombie processes can persist across pod restarts.
Teams face choices between manual orchestration, blue-green cluster migrations, or dynamic provisioning tools.
We asked: How do you handle node rebuilds and patching in Kubernetes?

The shift toward dynamic provisioning represents a transition from manual processes to declarative automation.
The relatively even split between approaches (27% manual, 26% blue-green, 41% dynamic) captures an industry inflection point rather than settled practice.
Node rebuilds involve complex coordination: ingress controllers need warmup time, Prometheus memory usage differs between old and new nodes, and load balancers require preparation.
For GPU-enabled nodes, additional complexity includes CUDA context cleanup and driver version consistency across the fleet.
Karpenter is particularly suited for AI/ML workloads because it provisions nodes based on real-time resource requests rather than pre-defined pools.
This matches the variable nature of training and inference workloads better than static node pool definitions.
The small "other" category (6%) suggests these four strategies genuinely capture how most organizations handle node lifecycle management.
What this means for you: Organizations currently using manual orchestration should evaluate whether that approach scales with their workload diversity.
Manual processes require deep operational knowledge that may not transfer when team members change.
Dynamic provisioners like Karpenter provide declarative configuration that documents intent and reduces operational burden.
However, the 27% still using manual orchestration aren't wrong—they're executing a valid strategy that becomes costlier as scale and workload types increase.
The transition to automation should happen when operational overhead exceeds the learning investment required for new tools.
Platform Distribution and Engagement
Responses came from four platforms with distinct participation patterns:
- LinkedIn: 689 responses (75%) - Highest volume and most substantive discussion. Generated detailed comments, reposts with commentary, and multi-threaded conversations. Primary platform for enterprise Kubernetes practitioners.
- Telegram: 121 responses (13%) - Strong technical engagement despite lower volume. Highest comment-to-response ratio with practitioners sharing specific implementation details. Tight-knit technical community.
- Twitter: 91 responses (10%) - Minimal comment activity but voting patterns aligned with LinkedIn. Functions primarily for polling rather than discussion.
- Mastodon: 16 responses (2%) - Lowest engagement across both voting and comments.
Summary
Most organizations operate far below the theoretical limits their cloud providers advertise, yet still struggle with fundamental efficiency challenges.
The gap between having GPU resources and using them productively suggests the bottleneck has shifted from infrastructure availability to organizational capability—teams need training, clear use cases, and operational maturity more than additional hardware.
The architectural choices reflect this maturity gradient.
Teams favoring unified clusters with proper orchestration demonstrate confidence in their platform capabilities, while those choosing separation acknowledge they're still building foundational skills.
Neither approach is wrong; they represent different points on the operational maturity curve.
Perhaps most telling is the shift toward automation.
The 41% using dynamic provisioners have recognized that manual processes don't scale with workload diversity.
Yet the 27% still orchestrating manually aren't struggling—they've chosen operational simplicity over tooling complexity, a valid trade-off at their current scale.
The path forward isn't about matching the hyperscalers' infrastructure specs.
It's about honest assessment of current capabilities, investment in the skills that unlock productive GPU use, and architectural decisions that match organizational maturity rather than aspirational benchmarks.